Actor Mesh#
What is an Actor Mesh?#
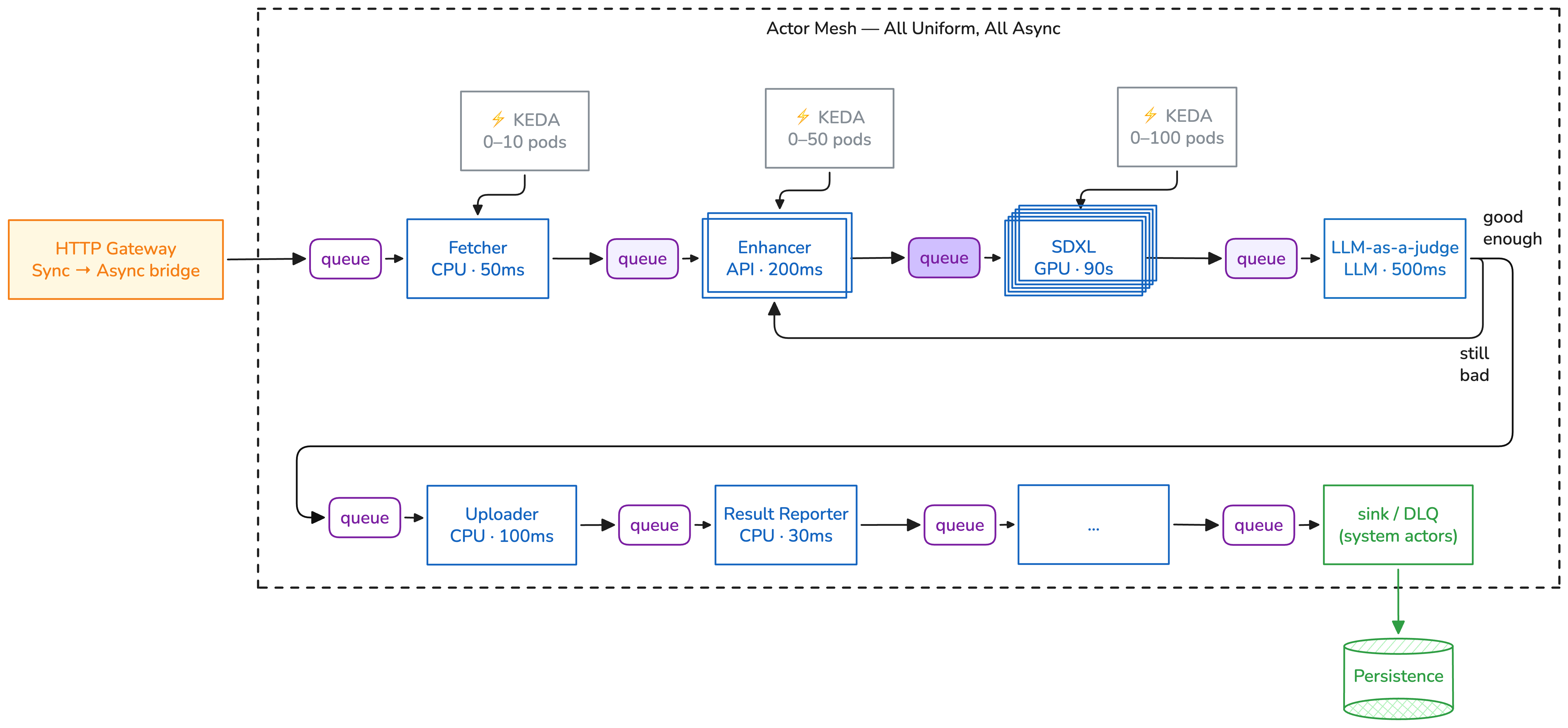
An 🎭 actor mesh is a network of stateless actors communicating through message queues. Each actor is an independent Kubernetes workload that receives envelopes, processes them, and forwards results to the next actor.
Click the diagram to view full size.
The key property: the message knows the way. Every envelope carries its own route
(prev/curr/next), so actors don't need to know about each other. There is no central
coordinator deciding what happens next.
Choreography vs Orchestration#
Most AI/ML pipeline frameworks use orchestration — a central coordinator (scheduler, DAG engine, or state machine) that controls the flow:
Orchestrator
|
+---> Step A ---> result ---> Orchestrator
| |
+---> Step B ---> result ---> Orchestrator
| |
+---> Step C ---> result ---> done
Asya uses choreography — each step knows only its own job, and the message carries the routing:
Queue A ---> Actor A ---> Queue B ---> Actor B ---> Queue C ---> Actor C ---> x-sink
(scales (scales (scales
0-10) 0-50) 0-100)
Why This Matters for AI Workloads#
Independent scaling#
In an orchestrated system, scaling the bottleneck means also scaling the orchestrator. In a mesh, each actor scales independently based on its own queue depth:
- Preprocessor (CPU, fast): 0-20 pods, scales on queue length 10
- LLM inference (GPU, slow): 0-5 pods, scales on queue length 1
- Postprocessor (CPU, fast): 0-10 pods, scales on queue length 5
GPU pods cost nothing when idle. KEDA scales them to zero between batches.
No single point of failure#
A central orchestrator is a single point of failure. If it crashes, all pipelines stall. In a mesh, a crashed actor affects only its own queue — messages accumulate until replicas recover. Other actors continue processing independently.
Queue-native resilience#
Messages are durably queued (SQS, RabbitMQ, GCP Pub/Sub). If an actor pod is evicted mid-processing, the message becomes visible again and another replica picks it up. No checkpointing logic needed in your code.
Dynamic routing#
Actors can modify route.next at runtime. An LLM judge can prepend different
actors at the front of the remaining route based on confidence:
def judge(state: dict):
if state["confidence"] > 0.9:
yield "SET", ".route.next[:0]", ["store"]
else:
yield "SET", ".route.next[:0]", ["human-review"]
yield state
Using .route.next[:0] prepends without discarding the remaining route.
This is impossible in a static DAG — you'd need to rebuild the graph at runtime.
The Trade-offs#
Choreography is not universally better. Choose orchestration when:
| Concern | Orchestration | Choreography (Asya) |
|---|---|---|
| Adding a new step | Change the DAG definition | Deploy a new actor; update the route |
| Debugging a failure | Read the orchestrator's execution log | Trace the envelope by trace_id across actor logs |
| Scaling a bottleneck | Scale the orchestrator + the worker | Scale only the bottleneck actor |
| Handling a crash | Orchestrator must checkpoint and resume | Queue redelivers the message |
| Global visibility | Orchestrator has a complete view | Aggregate from per-actor metrics |
Use orchestration for: simple 2-3 step workflows, strong consistency requirements, sub-100ms latency, small-scale deployments.
Use Asya for: multi-step AI/ML pipelines, bursty GPU workloads, agentic patterns with dynamic routing, cost-sensitive deployments that need scale-to-zero.
Further Reading#
- Core Concepts — envelope, actor, sidecar, routing
- Motivation — choreography vs orchestration trade-offs in depth
- Architecture — components, protocols, data flow
- Flow DSL — write pipelines as Python, compile to actors