Motivation#
The Starting Point#
AI-powered food image enhancement at Delivery Hero: take a restaurant photo, enhance it with SDXL, score quality with an LLM judge, upload if good enough. A multi-step pipeline running on Vertex AI / KFP with GPU acceleration.
It worked — until it didn't.
The Nightmare at Scale#
At production load, the synchronous architecture collapses:
- Rate limits: external AI APIs return 429. Clients retry with exponential backoff. While they wait, the server is idle too — everyone is sleeping
- Cascading failures: one slow LLM call holds a connection open. Upstream callers time out. Retries multiply. The pipeline stalls
- Wasted compute: GPU pods sit idle during backoff. You pay for 24/7 what you need for minutes
- Coupled scaling: the entire pipeline scales as one unit, even when only the GPU step is bottlenecked
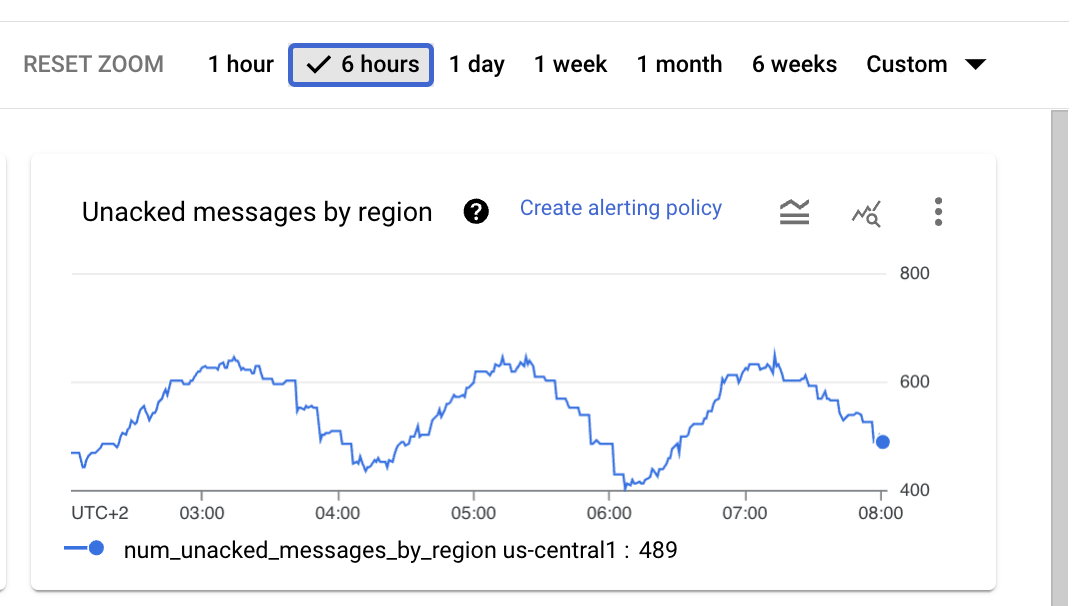
Before: 400-800 unacked messages oscillating — the system cannot drain its queue.
The Obvious Fix: Add a Queue#
The first fix is obvious: put a message queue in front of the GPU workers. Now callers don't block — they enqueue and move on. GPU workers pull at their own pace.
But this only fixes one step. The rest of the pipeline still has the same problems: retry logic in application code, coupled failure domains, monolithic scaling. You've added a queue to one bottleneck, but the architecture is still fundamentally synchronous.
The Real Fix: Flatten Everything#
What if every step had a queue? What if every step scaled independently? What if retry logic, timeouts, and error routing were infrastructure concerns, not application code?
This is the actor mesh: flatten the entire pipeline into independent actors connected through queues.
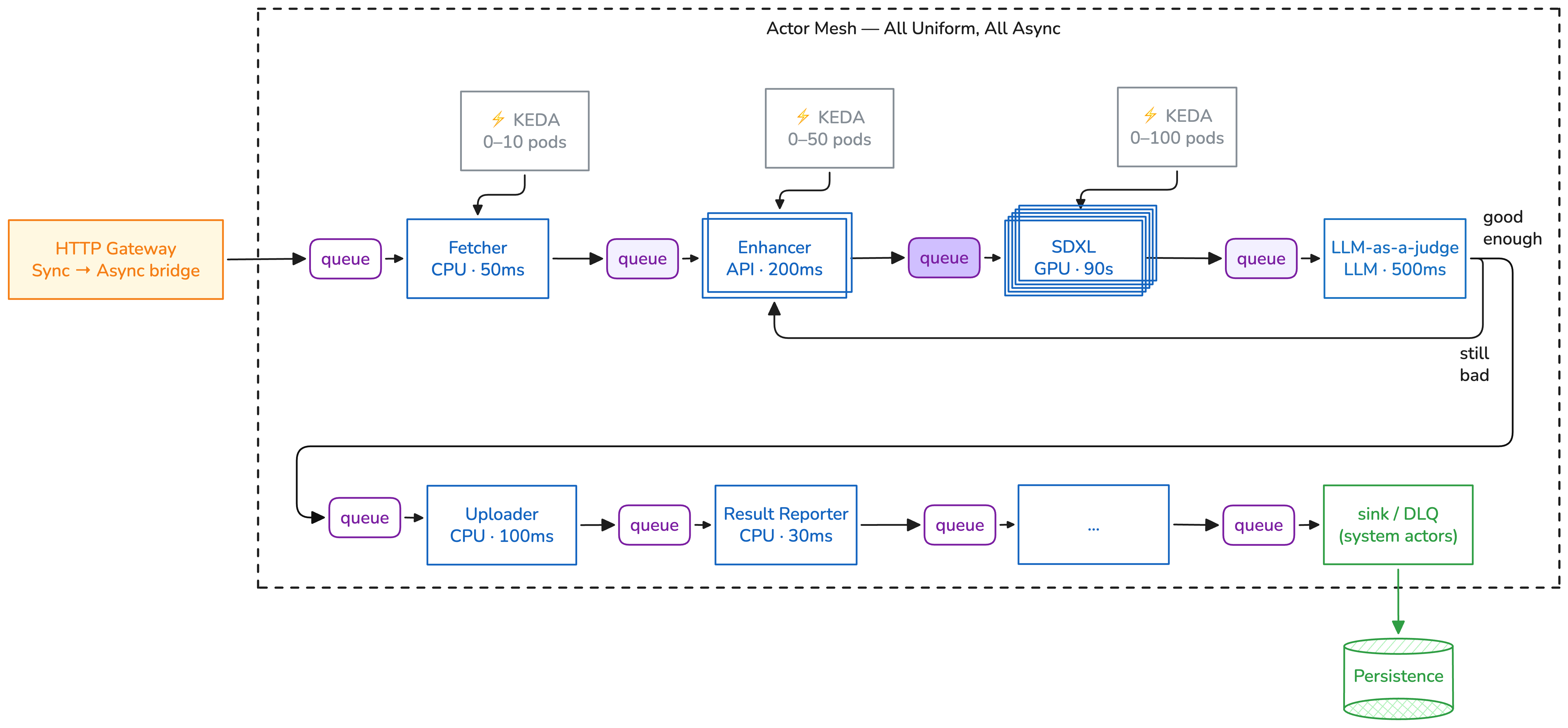
Actor Mesh: each actor scales independently, messages carry their own route
Each actor: - Has its own queue (SQS, RabbitMQ, Pub/Sub) - Scales independently from 0 to N via KEDA - Fails independently — a crashed actor doesn't stall others - Runs a pure Python function — no retry logic, no queue client, no SDK - Is able to re-route each message to another actor
Independent scaling in action:
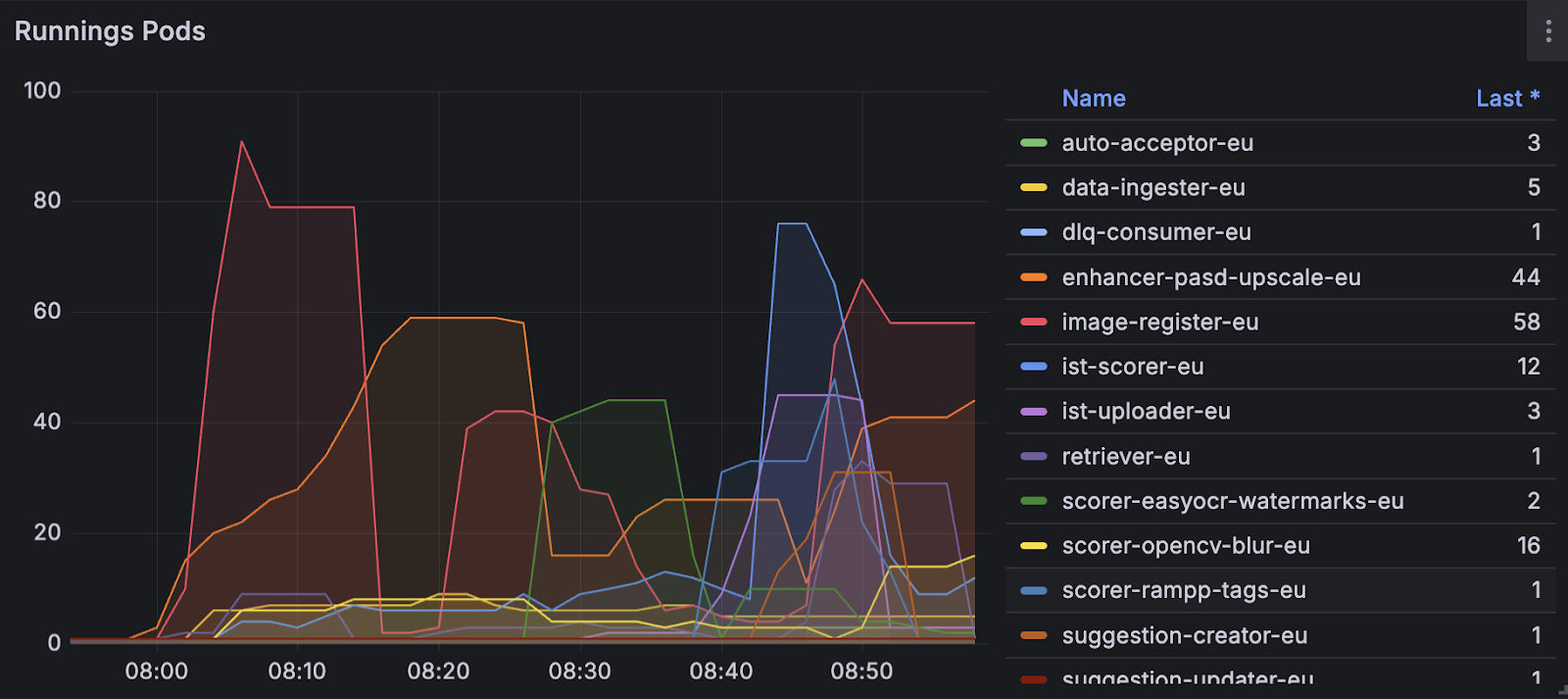
After: each actor scales independently. Enhancer peaks at 44 pods while retriever stays at 1. The system self-balances.
Two Files, Two Owners#
The handler is a pure Python function. No @retry, no ThreadPoolExecutor, no
sleep(backoff). Just business logic:
def answer_questions(payload: dict) -> dict:
payload["answers"] = [call_model(q) for q in payload["questions"]]
return payload
The infrastructure — retries, timeouts, scaling, transport — lives in the AsyncActor manifest, owned by the platform team:
apiVersion: asya.sh/v1alpha1
kind: AsyncActor
metadata:
name: model-caller
spec:
image: call-model:latest
handler: handler.answer_questions
scaling:
minReplicaCount: 0
maxReplicaCount: 3
resiliency:
actorTimeout: 300s
policies:
default:
maxAttempts: 5
backoff: exponential
initialInterval: 1s
maxInterval: 60s
flavors: [llm-resilient]
Complexity moves from application code to deployment configuration. Platform engineers pre-configure flavors (reusable templates) so data scientists never touch retry policies or scaling thresholds.
The Message Knows the Way#
Every message carries its own route — prev/curr/next — so there is no central
coordinator deciding what happens next:
{
"id": "a1b2c3d",
"route": { "prev": ["enhance"], "curr": "score", "next": ["validate"] },
"payload": { "image_url": "s3://cat.jpg", "enhanced_img": "supercat.jpg" }
}
Actors can even rewrite the route at runtime — an LLM judge can route high-confidence results directly to storage while sending uncertain results back for human review. This is choreography: no coordinator, no single point of failure, no coupled scaling.
REST in Peace. Long Live the Queue.#
| Before (REST) | After (Actor Mesh) |
|---|---|
| POST /predict and wait | Queue it, the message knows the way |
| Static pre-built pipeline | Dynamic mesh — actors write the future |
| Retry/timeout/backoff in your code | Retry policy is deployment configuration |
| One pipeline process, one failure domain | Independent actors, independent scaling |
| Framework or AI provider lock-in | Pure Python function + Pure K8s manifest |
When to Use Asya#
✅ Mixed-latency pipelines — fast backend steps (ms), LLM calls (seconds), and slow generative AI for images/video (minutes) all in the same pipeline, each scaling to its own hardware profile
✅ Big teams with separation of concerns — part of a developer platform on K8s where data scientists write Python and platform engineers manage infrastructure. Actors are the contract between the two worlds
✅ Scale to infinity at constant cost — KEDA scales each actor independently from zero. GPU pods cost nothing when idle. 10x traffic spike scales only the bottleneck, not the whole pipeline
✅ True decentralization — no central orchestrator that can fail, bottleneck, or become the deployment dependency for every team. Each actor is independently deployable, scalable, and replaceable
✅ Agentic workflows — dynamic routing, LLM judge loops, human-in-the-loop pause/resume, agent swarms as distributed actors
✅ Bursty or unpredictable workloads — batch processing that runs hourly, daily, or on-demand. Scale to zero between runs
When to Consider Alternatives#
❌ Quick prototyping without Kubernetes — if you don't have a K8s cluster and just need a fast PoC, Python-native frameworks (LangGraph, CrewAI) are simpler to start with. Once you need to scale beyond a single process, Asya is the path forward.
❌ LLM training — training requires fast cross-GPU synchronization (NCCL, ring allreduce) which is fundamentally different from Asya's async decentralized execution model. You may want to use other tools like Ray Train for training. Asya handles everything that happens around training: data preparation, inference, evaluation, serving.